

引言
为什么要整理关于python处理excel数据的一些知识点?
自己在做光伏结构二次开发的过程中有很多的数据需要去处理,如果能够将这些数据都写入excel表里面,然后对表里面的数据进行相应的操作,就能够把一些数据快速筛选出来,然后可以从中提取一些有用的结论。如何使用 python 对 excel 文件进行读取、写入就成为了最重要的方面,需要自己去掌握。其中,读取使用的库为 xlrd,写入使用的库为 openpyxl,所描述的方法并不是唯一的方法,但也能处理日常工作中的需要了。以下就主要说的关于创建execl文件一起其中的一些基础操作以及直接读取excel文件。
基础性理解
一个excel电子表格文档称为一个"工作簿",一个工作簿保存在.xlsx的文件中,每个工作簿可以包含多个表(也称之为工作表),用户当前查看的表(或关闭excel前最后查看的表)称为活动表。
工作簿(workbook)是一个openpyxl.workbook.workbook.Workbook的对象(可以通过打印一个workbook数据类型看出来),这是一个可迭代对象,可以进行for循环来获取工作表(sheet),后面的代码有相应的演示。
每个表(sheet)都有一些列(单元地址从A开始的字母)和一些行(地址从1开始的数字),处于特定行和列的方格称为单元格,每个单元格包含一个数字或者文本值,或者是空白,单元格形成的网格和数据构成了表。
读取 Excel 文件
主要思路:通过文件路径,打开工作簿
方法一:使用xlrd库
局限性:xlrd1.2.0之后的版本不支持xlsx格式,支持xls格式,如果采用.xlsx的格式会弹出
Excel xlsx file; not supported
解决办法:
方法一:卸载新版本,安装老版本pip uninstall xlrdpip install xlrd==1.2.0(或者更早的版本)方法二:将xlrd用到的excel版本修改为xls(保险起见,另存为xls格式)
相关代码如下:
from xlrd import open_workbook
if __name__ == "__main__":
# 此处为了能够调试成功,将原本的.xlsx的格式改为了.xls格式就可以正常运行
xls_file = 'test1.xls'
xls = open_workbook(xls_file) # 打开 excel 文件
sheet = xls.sheet_by_index(0) # 通过索引获取第 1 个表格中的内容,一个 excel 文件可能会包含多个表格
col1 = sheet.col_values(0) # 通过索引获取表格中第 1 列的内容
row1 = sheet.row_values(0) # 通过索引获取表格中第 1 行的内容
ele1 = sheet.cell_value(1,1) # 通过索引获取表格中第 2 行第 2 列的值(前提是表里第二行第二列确实有相应的值,否则会弹出索引出错)
ele2 = sheet.cell(1,1).value # 通过索引获取表格中第 2 行第 2 列的值,与上一行结果一样
print(ele1,ele2)方法二:使用openpyxl库
from openpyxl import load_workbook
from openpyxl.workbook.workbook import Workbook, Worksheet
from openpyxl.cell.cell import Cell# 打开已有的工作簿:load_workbook(filename),其中filename代表工作簿的路径
wb = load_workbook('test1.xlsx')# 运行代码后返回一个工作簿对象,这里多加了一个参数,打印相应的类型
print(wb, type(wb))
# 打印具有可迭代性的工作簿(本质就是一个列表迭代器)
# workbook是一个与列表一摸一样的列表迭代器,因此workbook也可以利用列表取值的方式进行取值
print(iter(wb))
print(iter([1, 3, 'a']))
print(iter('abc'))附注理解:Workbook是一个类,用于创建Excel对象(也就是Workbook对象),wb=Workbook()就相当于创建了一个空白的excel,用wb来索引,然后就可以向wb中添加内容
load_workbook是一个函数,这个函数接收一个Excel文件路径,然后会返回一个Excel对象(也就是Workbook对象),这个返回的Excel对象是通过指定的Excel文件创建的,因此self.wb里边是有可能有内容的,而不是一个空的Excel
一些读取的总结与验证for循环遍历工作簿中的所有工作表
Workbook是一个类,用于创建Excel对象(也就是Workbook对象),wb=Workbook()就相当于创建了一个空白的excel,用wb来索引,然后就可以向wb中添加内容
load_workbook是一个函数,这个函数接收一个Excel文件路径,然后会返回一个Excel对象(也就是Workbook对象),这个返回的Excel对象是通过指定的Excel文件创建的,因此self.wb里边是有可能有内容的,而不是一个空的Excel
for循环遍历工作簿中的所有工作表
既然workbook是一个列表迭代器,那就可以用 for 循环:
for i in wb:
print(i)输出:
<Worksheet "Sheet1">
<Worksheet "Sheet2">列表取值的方式读取工作表
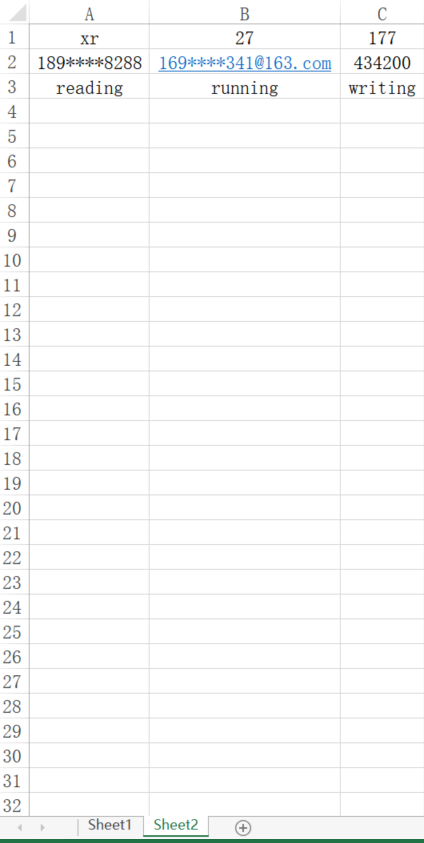
ws = wb['Sheet1']
print(iter(ws))
for i in ws:
print(i)
print(ws['A2'])输出:
<generator object Worksheet._cells_by_row at 0x0000023AFF81D9E0>
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>)
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>)<Cell 'Sheet1'.A2>通过上述代码发现,工作表sheet也是一个可迭代对象,通过for循环可以获取到每个单元格,以每一行作为一个元组
获取当前工作表
当前工作表的意思启动Excel文件时,打开的第一个工作表,比如:初始默认是打开sheet1,之后再sheet2中编辑内容保存后,关闭Excel文件再次启动时,会默认打开sheet2而不是sheet1,此时wb.active就是sheet2了
# 激活工作表
ws=wb.active获取工作表的最大行列数
max_r = ws.max_row #最大列
max_c = ws.max_column #最大列创建Excel文件
刚总结了读取Excel的一些方式,当Excel本身就不存在的时候,需要创建workbook,并且保
import openpyxl
# 创建了一个excel,只不过打开在内存里面了(creat a excel file in RAM)
wb = openpyxl.Workbook()
# 获取当前active的sheet,并将名字改为mysheetwb.active.title='mysheet'
# 保存文件,并将名字改成test
wb.save("test2.xlsx")存.

获得、创建、删除sheet表
使用场景:获取相应的表单、以及在原有的表单的基础上增加表
sheet_list = wb.worksheets
# 可通过索引指向不同表sheet_list[0]、sheet_list[1]
# print(sheet_list)name_list = wb.sheetnames
# 取得工作簿中所有表名的列表# print(name_list)
sheet = wb['Sheet1'] # 传递表名字符串获得该表
sheet = wb.active # 取得工作簿的活动表,即工作簿在Excel打开时出现的工作表
wb.create_sheet("mysheet1")
# 调用create_sheet()方法,就能在相对应的excel中创建一个sheet# 在方法中指定下标:在特定位置创建表wb.create_sheet(index=1, title="mysheet")
# 这里本来已经有两个表单,然后创建了一个mysheet1,这里插入了一个索引为3的表,也就是在mysheet1后面加入一个mysheet2表wb.create_sheet(index=3, title="mysheet2")# 删除表:
# 方式一:wb.remove(wb["mysheet1"])
# 方式二:del wb["mysheet2"]
# 操作之后节点要保存,不然上面的操作是不能反映在文件中的
wb.save("test1.xlsx")
name_list = wb.sheetnames
print(name_list)输出内容如下:# 表明最开始有Worksheet
[<Worksheet "Sheet1">, <Worksheet "Sheet2">]
# 表明两个表单的名字分别是:"Sheet1" 和 "Sheet2"
['Sheet1', 'Sheet2']
# 通过增加两个表单后名字分别是:"Sheet1" 、 "Sheet2"、"mysheet1"、"mysheet2"['Sheet1', 'Sheet2', 'mysheet1', 'mysheet2']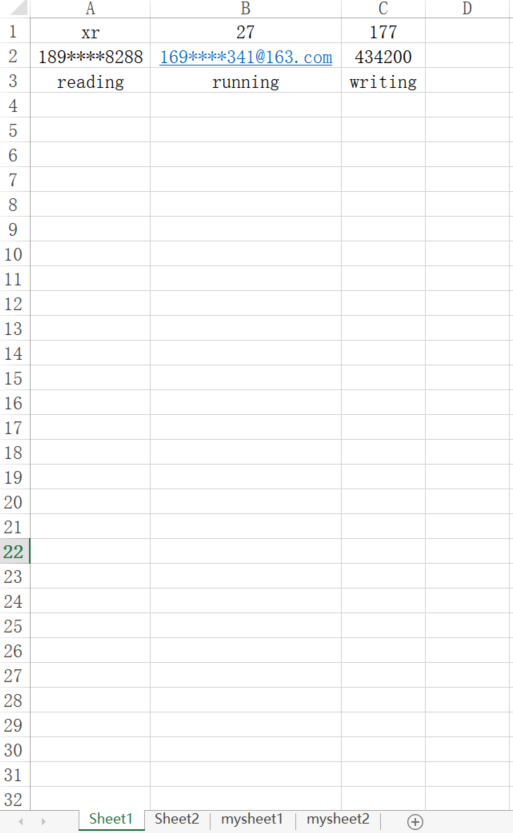
获得cell对象(单元格)有了Worksheet对象后,就可以按照名字访问Cell对象
cell对象有一个value属性,它包含这个单元格中保存的值,cell对象也有row、column和coordinate属性,都可以用来提供单元格的位置信息。
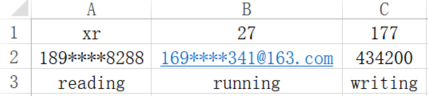
c = sheet['A1'] # 获得单元格;c.value # 获得单元格中的值;
c.row # 获得单元格的横坐标数字;
c.column # 获得单元格的纵坐标字母;
c.coordinate # 获得单元格的坐标字符串;
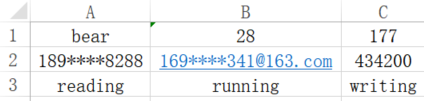
sheet['A1'] = 'bear' # 可直接更改单元格中的值
c = sheet.cell(row=1, column=2) # 通过cell方法和它的关键字参数得到cell对象(也可使用位置参数);sheet.cell(1, 2, '28') # 可以更改单元格的值
wb.save("test1.xlsx")
有了Worksheet对象后,就可以按照名字访问Cell对象
cell对象有一个value属性,它包含这个单元格中保存的值,cell对象也有row、column和coordinate属性,都可以用来提供单元格的位置信息。
c = sheet['A1'] # 获得单元格;c.value # 获得单元格中的值; c.row # 获得单元格的横坐标数字; c.column # 获得单元格的纵坐标字母; c.coordinate # 获得单元格的坐标字符串; sheet['A1'] = 'bear' # 可直接更改单元格中的值 c = sheet.cell(row=1, column=2) # 通过cell方法和它的关键字参数得到cell对象(也可使用位置参数);sheet.cell(1, 2, '28') # 可以更改单元格的值 wb.save("test1.xlsx")
获取表行数与列数,列字母与数字的相互转换# 可以通过 Worksheet 对象的 max_row和 max_column,maXrow = sheet.max_row, maXcolumn = sheet.max_column均返回一个整数,确定表的大小
# 注意需要先从openpyxl.utils中引入后面需要的两个函数
from openpyxl.utils import get_column_letter,column_index_from_string
# 从字母转换到数字调用openpyxl.utils.column_index_from_string()函数
openpyxl.utils.column_index_from_string('AA')
# 从数字转换到字母调用openpyxl.utils.get_column_letter()函数
openpyxl.utils.get_column_letter(24)
获得行或列wb = load_workbook('test1.xlsx')
sheet=wb['Sheet1']
a=sheet['A1':'C3'] # 获得嵌套的元组,内层的元组是每一行单元格构成的,这里是3行三列
print(a)
# 要访问特定行或列的单元格的值
# 得到第二行构成的元组
# 方式一:用list(sheet.row)[1],得到第二行构成的元组
b=list(sheet.rows)[1]
print(b)
# 方式二:sheet['2'],直接得到第二行构成的元组
c=sheet['2']
print(c)
# 得到第一列构成的元组
# 方式一:list(sheet.columns)[0],得到第一列构成的元组
d=list(sheet.columns)[0]
print(d)
# 方式二:sheet['A'],直接得到第一列构成的元组
e=sheet['A']
print(e)
# 可以通过 Worksheet 对象的 max_row和 max_column,maXrow = sheet.max_row, maXcolumn = sheet.max_column均返回一个整数,确定表的大小
# 注意需要先从openpyxl.utils中引入后面需要的两个函数
from openpyxl.utils import get_column_letter,column_index_from_string
# 从字母转换到数字调用openpyxl.utils.column_index_from_string()函数
openpyxl.utils.column_index_from_string('AA')
# 从数字转换到字母调用openpyxl.utils.get_column_letter()函数
openpyxl.utils.get_column_letter(24)wb = load_workbook('test1.xlsx')
sheet=wb['Sheet1']
a=sheet['A1':'C3'] # 获得嵌套的元组,内层的元组是每一行单元格构成的,这里是3行三列
print(a)
# 要访问特定行或列的单元格的值
# 得到第二行构成的元组
# 方式一:用list(sheet.row)[1],得到第二行构成的元组
b=list(sheet.rows)[1]
print(b)
# 方式二:sheet['2'],直接得到第二行构成的元组
c=sheet['2']
print(c)
# 得到第一列构成的元组
# 方式一:list(sheet.columns)[0],得到第一列构成的元组
d=list(sheet.columns)[0]
print(d)
# 方式二:sheet['A'],直接得到第一列构成的元组
e=sheet['A']
print(e)输出的内容如下(通过打印我们可以非常直观的得到一些结果)
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>), (<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>), (<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>))
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>)
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>)设定字体格式# 设定字体方法
from openpyxl.styles import Font
wb = openpyxl.Workbook()
sheet = wb['Sheet1']
italic24Font = Font(name = '黑体', size = 16, italic = True) #将字体设置为24号斜体
sheet['A1'].font = italic24Font
wb.save("test1.xlsx") #记得保存
# 设定字体方法
from openpyxl.styles import Font
wb = openpyxl.Workbook()
sheet = wb['Sheet1']
italic24Font = Font(name = '黑体', size = 16, italic = True) #将字体设置为24号斜体
sheet['A1'].font = italic24Font
wb.save("test1.xlsx") #记得保存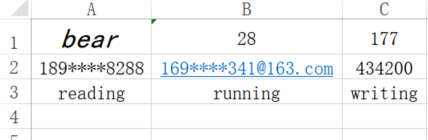
辅助理解:
Font()函数的关键字参数
| 关键字参数 | 数据类型 | 描述 |
| name | 字符串 | 字体名称,诸如’Calibri’ 或’黑体’ |
| size | 整型 | 大小点数 |
| bold | 布尔型 | True 表示粗体 |
| italic | 布尔型 | True表示斜体 |
公式的应用
# 在加载文件时,load_workbook()函数应该传入参数data_only=True,文档才能显示公式计算后的结果而不是公式本身import openpyxlwb = openpyxl.load_workbook("test1.xlsx", data_only = True)
sheet = wb.active# 在单元格E1填入C1与D1的比值
sheet['E1'] = '=C1/D1'
wb.save('test1.xlsx')
调整行列的高度与宽度
wb = openpyxl.load_workbook('test1.xlsx')
sheet = wb.active
sheet.row_dimensions[1].height = 20
#更改第一行的高度
sheet.column_dimensions['A'].width = 30
#更改第一列的宽度
wb.save('test1.xlsx')合并拆分单元格
# 合并、拆分单元格
wb = load_workbook('test4.xlsx')
sheet = wb.active# 将A1~C1的单元格合并sheet.merge_cells('A1:C1')
# 在A1单元格里面填入"四个单元格合并"
sheet['A1'] = '四个单元格合并'
wb.save('test4.xlsx')
# 同理可用sheet.unmerge_cells(‘A1:D1’)拆开合并的单元格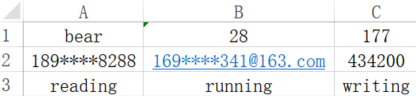

冻结行或列
# 冻结某一行或某一列,滚动时被冻结的行列不会被移出屏幕
wb = load_workbook("test4.xlsx")
sheet = wb.active
sheet.freeze_panes = 'B2' #B2单元格以上的行,以及以左的列被冻结,单元格所在的行与列并不会被冻结wb.save('test4.xlsx')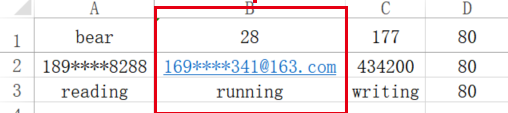
读取单元格
每个工作表都有各自的单元格,所以要读取指定的内容,先要指定工作表
指定行数和列数读取单元格
cell = ws.cell(row=2,column=1) # 读取单元格名称:A1、B3
cell = ws.cell(row=2,column=1).value # 读取单元格中的内容
一些注意事项:
通过cell 对象的value属性可以获取值
value只有两种数据类型:字符串、数值(数值以外的就是字符串)
如果cell里没有值,返回None
写入 Excel 文件
使用openpyxl库(也可以用xlwt库来写入excel,这里不再展示)
import openpyxl
# 创建了一个excel,只不过打开在内存里面了(creat a excel file in RAM)
wb = openpyxl.Workbook()
# 获取当前active的sheet,并将名字改为mysheet
wb.active.title='mysheet'
# 保存文件,并将名字改成test
wb.save("test2.xlsx")后记
后面尽量以实际的例子为主,一些比较复杂的用法也尽量边学习边整理,将一些用法揉进实际的案例中去比较好,也印象深刻。







